
K-Means Clustering
K-Means is a powerful unsupervised learning algorithm for clustering data into coherent subsets. It iteratively assigns points to the nearest centroid and updates centroids to minimize distortion, making it widely used in practice.
Machine Learning Learning Path
Anomaly Detection: Identifying Rare and Unusual Patterns in Data
K-Means Clustering
Given an *unlabeled dataset automatically group the data into coherent subsets, called clusters.
Cluster analysis is a powerful unsupervised learning technique for discovering groups in data.
Used to solves the clustering problem:
- one of the most widely used clustering algorithms.
- K-Means is an Iterative Algorithm
Input:
- number of clusters
- ,
- where .
Output: cluster assignments for each example and cluster centroids.
K-Means works as follows:
-
Takes and unlabeled data as input.
-
Repeats:
- Assign points to nearest centroid.
- Move centroids to mean of assigned points.
-
Minimizes Cost function (Distortion):
-
Stops when assignments stabilize.
It is simple, fast, and widely used in practice.
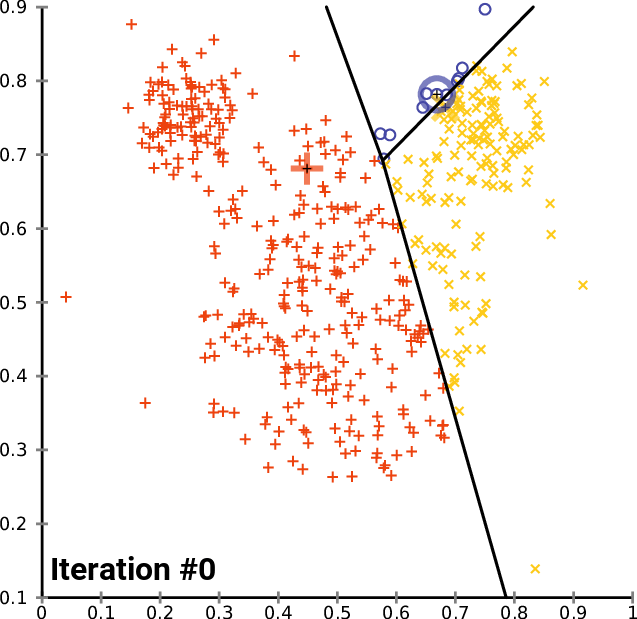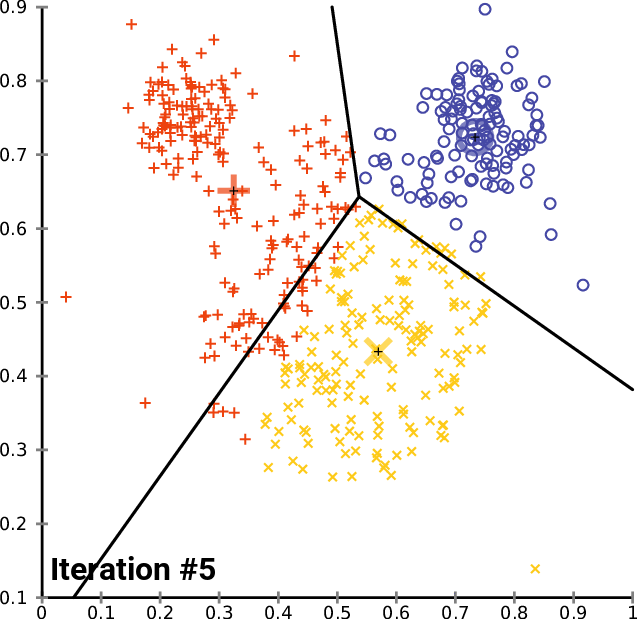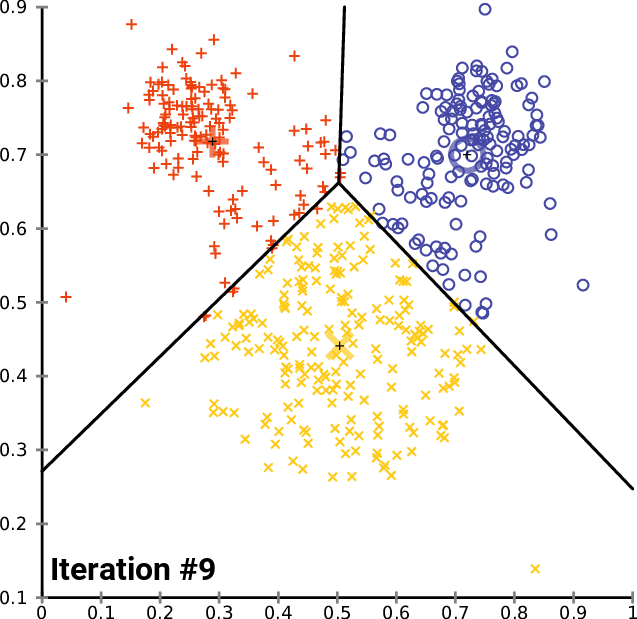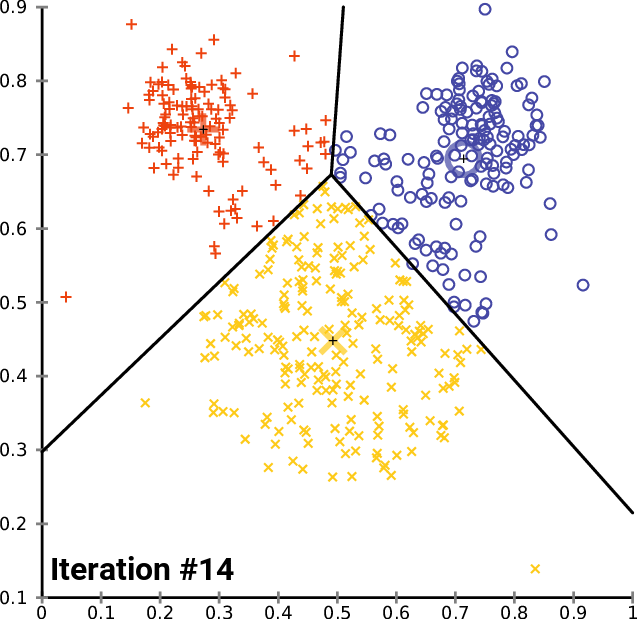
When K-Means Works Well
K-Means works best when:
- Clusters are roughly spherical.
- Clusters have similar sizes.
- Features are properly scaled.
Feature scaling is important:
Without scaling, features with larger magnitude dominate distance calculations.
When K-Means Struggles
K-Means performs poorly when:
- Clusters are non-convex.
- Clusters have very different densities.
- Data contains significant outliers.
- Clusters are not well separated.
K-Mean Algorithm
Suppose we want to group data into clusters.
Input 🍓🍡🍬🍭:
- (number of clusters) = 2 in this case
- Dataset , where
- = number of examples
Step 1: 🥣 Initialize Cluster centroids()
Randomly initialize cluster centroids
-
where
-
= total number of clusters
-
-
= centroid of cluster
-
is a point in the same space as the data (i.e., )
Choosing the Number of Clusters (K)
There is no universal rule for choosing .
Proper Random Initialization
When running K-Means:
Where:
- = number of clusters
- = number of training examples
It does not make sense to choose .
Recommended Initialization Method
- Randomly select distinct training examples.
- Set initial centroids equal to those examples:
where are randomly chosen distinct indices.
This ensures centroids start within the data distribution.
Elbow Method:
- Run K-Means for different values of .
- Compute distortion for each.
- Plot vs .
- Look for an “elbow” where improvement slows down.
Repeatedly Steps 2-3 until convergence {
Step 2. 📏 Cluster Assignment Step
For each training example() where :
Assign to the cluster with the closest centroid.
In Mathematical terms:
Index of Cluster
Index of cluster is Centroid closest to in
Examples:
- If is closest to , then
- If is closest to , then
= CLuster centroid of cluster
Value of centroid of cluster assigned to is
- If , then
- If , then
Which can be expressed as:
Formally:
Where:
- = centroid of cluster
- = cluster assigned to example
We typically use squared Euclidean distance.
Example
Given
Centroids:
Training example:
Distance to
Distance to
Distance to
Assigning Cluster
- Distance to : 4
- Distance to : 8
- Distance to : 25
The smallest distance is to so
Step 3. 🧿 Move Centroid Step
For each cluster where :
- = total number of clusters
Update centroid to be the mean of all points assigned to it.
Where:
- = set of points assigned to cluster
- = number of points in cluster
This moves the centroid to the center of its assigned points.
- Each centroid becomes the mean of the points assigned to it.
⛔ Stop Condition
The algorithm converges when:
- Cluster assignments no longer change, or
- Centroids stop moving.
What If a Cluster Gets No Points?
If some centroid has zero assigned points:
- Eliminate the cluster (resulting in clusters), or
- Reinitialize the centroid randomly
In practice, empty clusters are uncommon with reasonable initialization.
💰 Cost Function (Distortion)
Minimize th Distance between points and their assigned centroids.
Or equivalently:
Where:
- = cost function (distortion)
- = number of training examples
- = -th training example
- = centroid of the cluster assigned to
- = index of cluster assigned to
Each iteration consists of:
-
Assignment step
Minimizes with respect to (cluster assignments). -
Centroid update step
Minimizes with respect to (centroid locations).
Since each step does not increase , the algorithm is guaranteed to converge.
Each iteration of K-Means guarantees that does not increase.
However, it may converge to a local minimum, not necessarily the global minimum.
A good solution:
- Each natural cluster is captured by one centroid.
A bad solution:
- Merge two true clusters into one
- Split one true cluster into multiple parts
- Assign very few points to some clusters
All of these correspond to higher distortion:
To reduce the risk of poor local minima:
Algorithm
Repeat for :
- Randomly initialize centroids
- Run K-Means to convergence
- Compute distortion:
Finally: