
Understanding CLIP: Connecting Images and Text in Generative AI
Learn how OpenAI's CLIP model bridges vision and language by mapping images and text into a shared embedding space. Explore CLIP encodings, similarity search, zero-shot classification, and how CLIP powers modern text-to-image generation systems such as Stable Diffusion.
Understanding Model Fusion in AI Systems
Generative Adversarial Networks (GANs) Explained
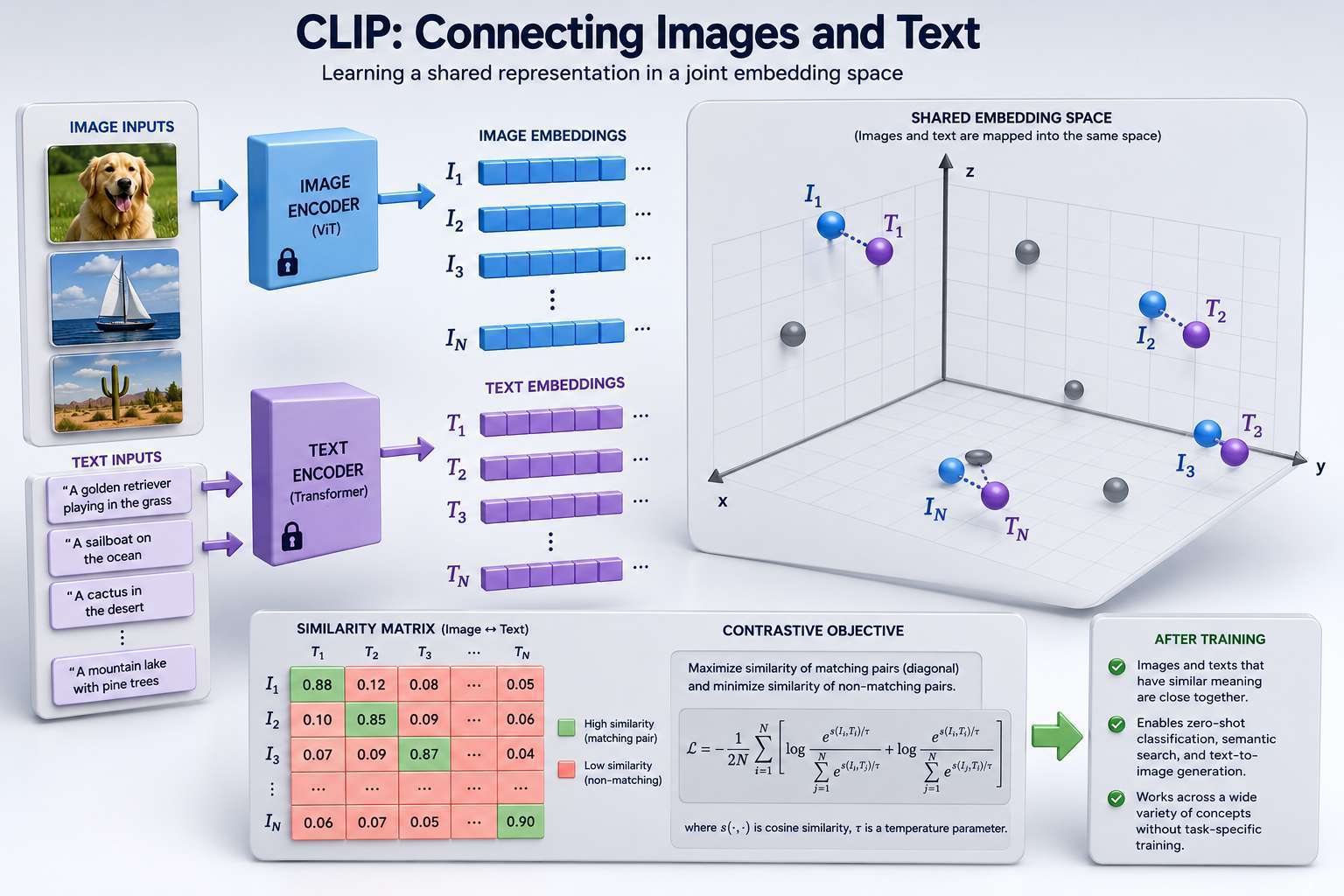
Understanding CLIP
The model learns to associate images with their corresponding text descriptions.
CLIP stands for:
Instead of training on a fixed set of labels, CLIP learns from millions of image-caption pairs.
Example:
Image:
Dog running on a beach
Caption:
"A dog running on a beach"
Over time, CLIP learns that these two pieces of information represent the same concept.
Connecting Images and Text in Generative AI
One of the biggest challenges in artificial intelligence is enabling machines to understand both images and language simultaneously.
Humans can easily look at a photograph and describe what they see:
A golden retriever running on a beach.
But teaching a neural network to connect visual concepts with natural language is far more difficult.
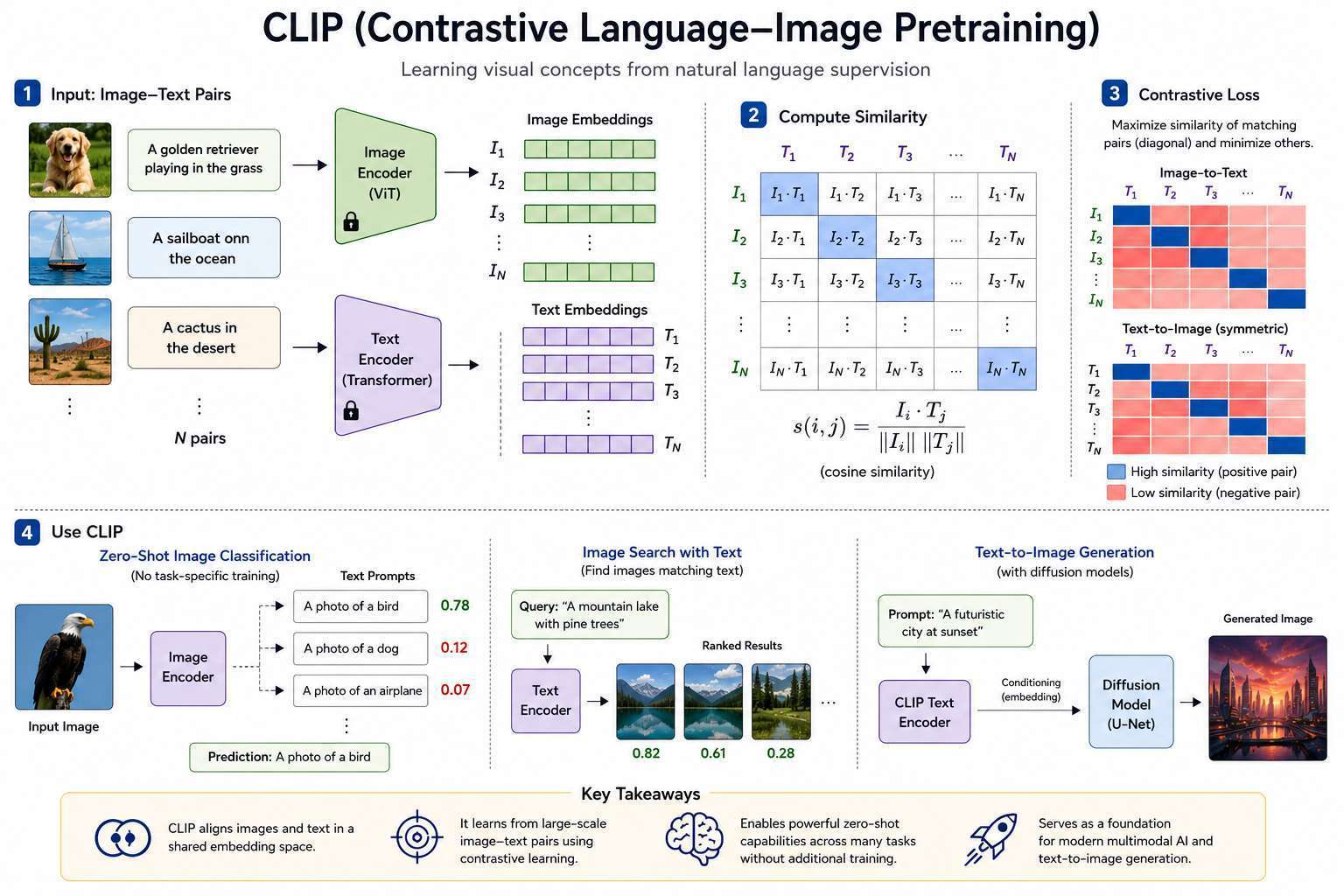
OpenAI's CLIP (Contrastive Language-Image Pretraining) was a major breakthrough in multimodal AI because it learned a shared representation of images and text.
Today, CLIP serves as a foundational component in many modern AI systems, including image search, zero-shot classification, multimodal assistants, and text-to-image generation models such as Stable Diffusion.
CLIP Architecture
CLIP contains two neural networks:
- Image Encoder
- Text Encoder
graph TD
Image[Input Image]
Text[Input Text]
ImageEncoder[Image Encoder]
TextEncoder[Text Encoder]
ImageEmbedding[Image Embedding]
TextEmbedding[Text Embedding]
Similarity[Similarity Measurement]
Image --> ImageEncoder
ImageEncoder --> ImageEmbedding
Text--> TextEncoder
TextEncoder --> TextEmbedding
ImageEmbedding --> Similarity
TextEmbedding --> Similarity
Both encoders map their inputs into a shared embedding space.
Understanding Embeddings
Embeddings are numerical representations of data.
For example:
Dog
may become:
Similarly:
Dog Image
may become:
The embeddings are close together because they represent similar concepts.
Training CLIP
Suppose we have:
Image 1 → Dog
Image 2 → Cat
Image 3 → Car
The model generates:
Image Embeddings
Text Embeddings
The Shared Embedding Space
CLIP's goal is to place related images and text near each other.
graph TD
DogText["Dog"]
DogText --> EmbeddingSpace
DogImage["🐕"]
DogImage--> EmbeddingSpace
CatText["Cat"]
CatText--> EmbeddingSpace
CatImage["🐈"]
--> EmbeddingSpace
Inside the embedding space Image and Label appear close together.
Dog Image ↔ Dog Text
Cat Image ↔ Cat Text
Goal of Training
CLIP learns to maximize:
while minimizing:
This is called Contrastive Learning.
Similarity Measurement
CLIP commonly uses cosine similarity.
Given two embeddings:
their similarity is:
Values close to:
indicate strong similarity.
Image Search Using CLIP
Suppose we have thousands of images.
Workflow:
graph TD
Query["Golden Retriever"]
--> TextEncoder
--> QueryEmbedding
Images
--> ImageEncoder
--> ImageEmbeddings
QueryEmbedding
--> SimilaritySearch
ImageEmbeddings
--> SimilaritySearch
SimilaritySearch
--> Results
The most similar images are returned.
This enables semantic image search.
Zero-Shot Classification
Traditional classifiers require training on every category.
CLIP can classify unseen categories without retraining.
Example:
A photo of a dog
A photo of a cat
A photo of a horse
Process:
graph TD
Image[Input Image]
Image --> CLIP
CLIP --> Similarity
Similarity --> Prediction
The category with the highest similarity wins.
Why CLIP Was Revolutionary
Traditional computer vision:
graph TD
Image[Input Image]
Image --> CNN
CNN --> Label
CLIP:
graph TD
Image[Input Image]
Image --> CLIP
CLIP --> Language
This created a much more flexible understanding of concepts.
CLIP and Text-to-Image Generation
One of CLIP's most important applications is guiding image generation.
Architecture:
graph TD
Prompt
--> CLIPTextEncoder
--> TextEmbedding
TextEmbedding
--> DiffusionModel
--> GeneratedImage
The text embedding acts as a guide for image generation.
Example: Stable Diffusion Architecture
A simplified Stable Diffusion workflow:
graph TD
Prompt
--> CLIP
--> TextEmbedding
TextEmbedding
--> UNet
--> Image
Components:
- CLIP Text Encoder
- U-Net Denoiser
- Diffusion Process
CLIP provides semantic understanding.
U-Net performs image generation.
How CLIP Enables Text-to-Image Models
Prompt:
A futuristic city at sunset
CLIP converts this into an embedding:
The diffusion model then generates an image that matches:
The generated image gradually becomes aligned with the text representation.
Example: CLIP + Diffusion Pipeline
graph TD
TextPrompt
--> CLIP
--> TextEmbedding
TextEmbedding
--> DiffusionModel
DiffusionModel
--> UNet
UNet
--> Image
This combination powers modern generative AI systems.
Applications of CLIP
Semantic Search
- Image retrieval
- Content recommendation
Zero-Shot Classification
- Object recognition
- Document categorization
Visual Question Answering
- Image understanding
- Multimodal assistants
Generative AI
- Stable Diffusion
- Image generation
- Image editing
Robotics
- Scene understanding
- Object identification
Advantages of CLIP
- Learns from natural language
- Zero-shot capabilities
- Strong multimodal understanding
- Flexible embeddings
- Works across diverse domains
Limitations
- Inherits biases from training data
- Struggles with fine-grained reasoning
- Not optimized for detailed localization
- Can misinterpret ambiguous prompts
Modern vision-language models often extend CLIP with larger architectures and additional reasoning capabilities.
Building a Simple Text-to-Image Neural Network
At a high level:
graph LR
Text
--> CLIPEncoder
--> Embedding
Embedding
--> Generator
--> Image
Training objective:
The generator learns to produce images whose CLIP embeddings match the text embeddings.
Loss:
This encourages generated images to align with the prompt.
CLIP in Modern Diffusion Models
Modern diffusion models separate responsibilities between different neural networks.
graph LR
Prompt
--> CLIP[CLIP Text Encoder]
--> Embedding
--> UNet[U-Net Denoiser]
--> Image
CLIP answers:
What should be generated?
U-Net answers:
How should the image be generated?
Together they form the foundation of modern text-to-image systems.
Final Thoughts
CLIP fundamentally changed how AI systems connect language and vision.
Instead of treating images and text as separate domains, CLIP maps both into a shared semantic space.
The workflow can be summarized as:
This simple but powerful idea has become a cornerstone of multimodal AI and is one of the key technologies behind modern text-to-image generation systems, semantic search engines, and vision-language models.
The evolution can be summarized as:
Without CLIP-style multimodal embeddings, many of today's most impressive text-to-image and vision-language systems would not be possible.